今日,小米正式推出MiMo-V2.5语音模型体系,涵盖语音识别与合成双核心模块,构建全链路语音交互能力。
该系列包含MiMo-V2.5-ASR与MiMo-V2.5-TTS两大分支,前者在复杂场景下表现突出,支持中英双语、方言混用、强噪音环境及多说话人场景,知识密度处理能力达行业领先水平。
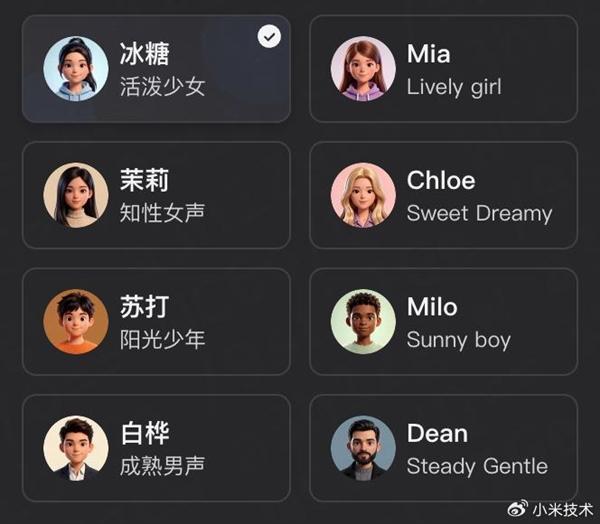
TTS模块细分三大功能模型:基础版MiMo-V2.5-TTS内置多款调优音色,支持语速、情绪等维度精细控制;VoiceDesign版通过自然语言描述生成音色,可自定义年龄、口音、性格等特征,兼容矛盾描述;VoiceClone版仅需数秒音频即可克隆真人音色,保留气息、节奏等细节特征,并支持叠加创作指令。
目前,上述TTS模型已在小米MiMo API平台开放限时免费服务,覆盖多场景语音创作需求。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 yyfuon@163.com 举报,一经查实,本站将立刻删除。如若转载,请注明出处:https://www.ipsmc.com/3cshuma/483.html





